Projects
IoT Monitoring Platform
A growing platform covering all layers of a real IoT system — from secure device ingestion through a Kafka gateway to behavioral analytics and an AI assistant that answers questions about the live data. Built around a conference room monitoring use case (temperature, humidity, occupancy, motion), with a deliberate focus on clean architecture, infrastructure as code, and engineering practices that hold up in production. 403 tests across seven projects, 80%+ coverage enforced on every push via GitHub Actions.
Serverless REST API for real-time sensor event ingestion with threshold-based anomaly detection. Clean layered architecture (models → services → repositories). Full infrastructure as code with CloudFormation. Deployed to AWS via CI/CD.
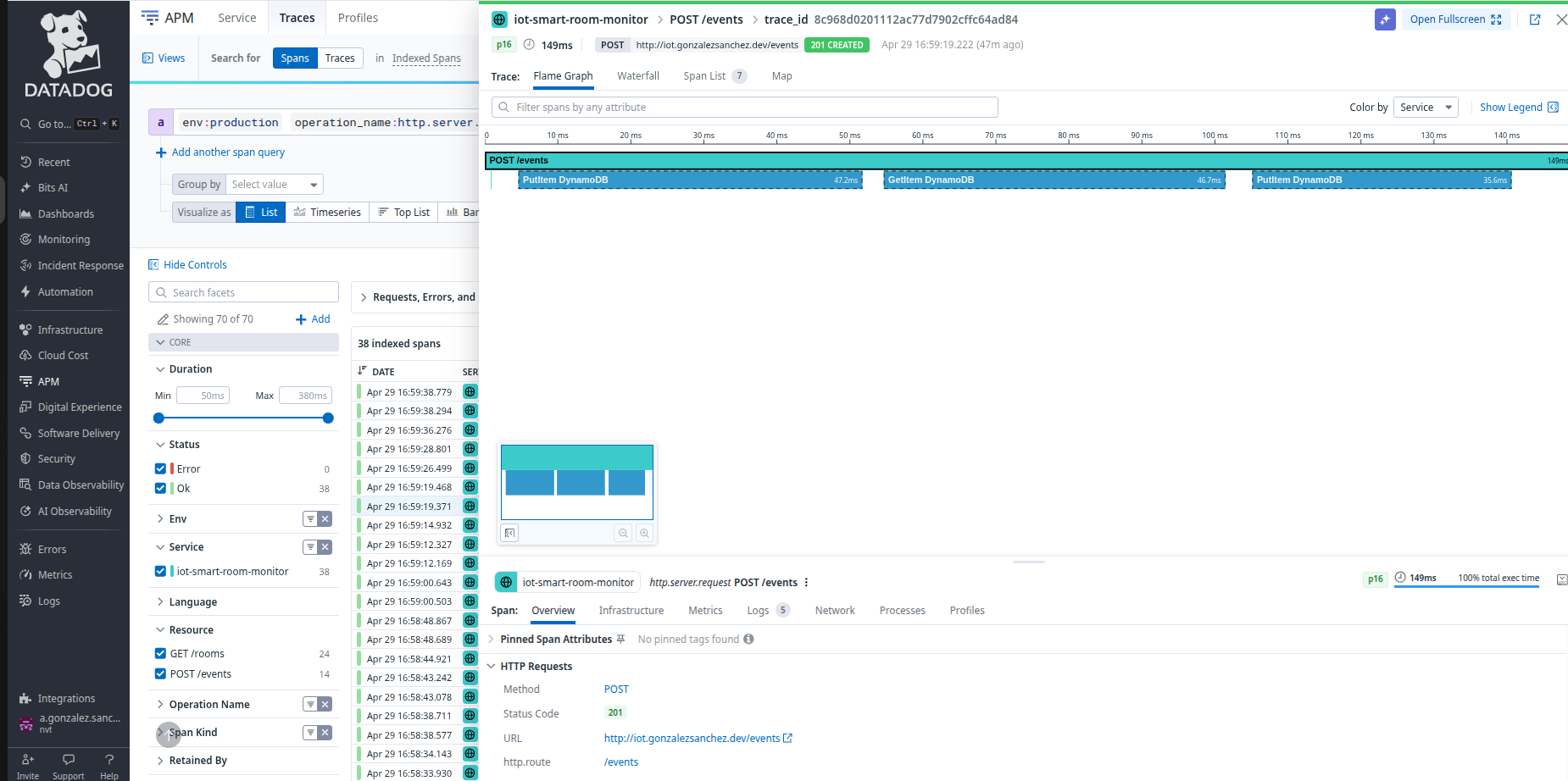
Same domain logic as 1a, redeployed as a containerised FastAPI app. End-to-end observability with OpenTelemetry auto-instrumentation → OTel Collector → Datadog APM: distributed traces with automatic DynamoDB child span detection, log-trace correlation, and Watchdog anomaly detection — zero manual instrumentation.
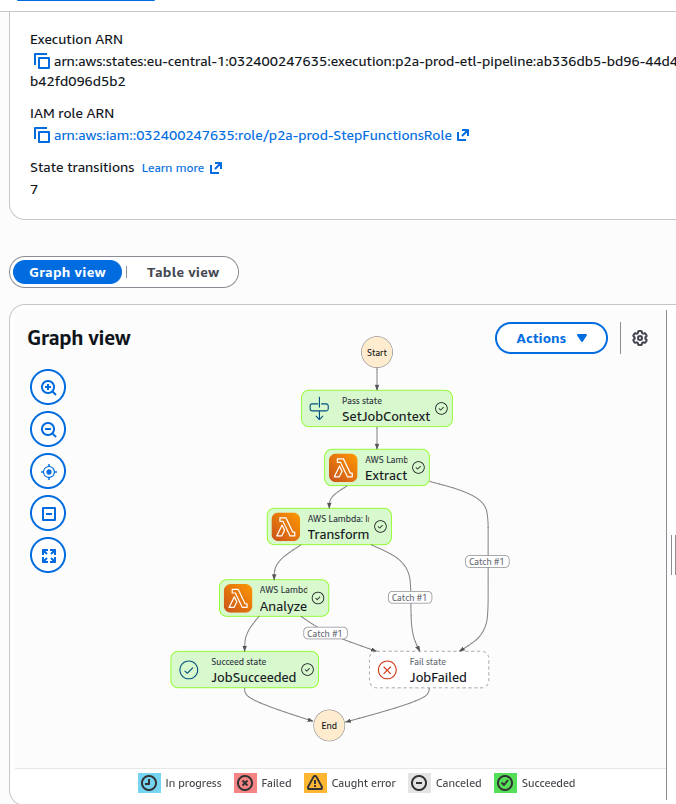
Serverless ETL pipeline: extracts historical sensor data from DynamoDB, detects occupancy schedules, temperature trends and anomalies, stores results in Aurora Serverless v2 (PostgreSQL). Full Terraform infrastructure. Runs on-demand to minimise costs.
Same analytics goal as 2a, re-implemented with a data engineering stack. Medallion architecture (Bronze → Silver → Gold): raw Parquet → processed Parquet → PostgreSQL via dbt. PySpark analytics: occupancy schedules, temperature trend regression (regr_slope), z-score anomaly detection, spatial hotspots (GeoPandas). Observability via OTel → Grafana Cloud. Power BI dashboard live in the frontend. Deployed via a 9-stage Jenkins CD pipeline (Groovy Jenkinsfile).
Same analytics domain as 2b, rebuilt on a fully managed Azure stack. Bronze ingestion via Auto Loader, Silver transformation with the Write-Audit-Publish pattern (good records MERGEd idempotent, invalid records to quarantine — never deleted), Gold layer with dbt-databricks incremental models: z-score anomaly detection, hourly aggregations, dimensional models. Full IaC via Terraform. Monthly job on the 1st at 06:00 Brussels time via Databricks Asset Bundles. Gold data served live via FastAPI /lakehouse/* endpoints.
Secure device layer for the platform: device registration with bcrypt-hashed API keys, short-lived JWT session tokens and per-device sliding-window rate limiting. Async FastAPI producer publishes sensor events to Kafka (Redpanda); a consumer group normalises them to the shared DynamoDB contract with idempotent writes — poison messages go to a dead-letter queue with full error context. CloudFormation IaC, CLI device simulator and Locust load-test suite integrated in CI.
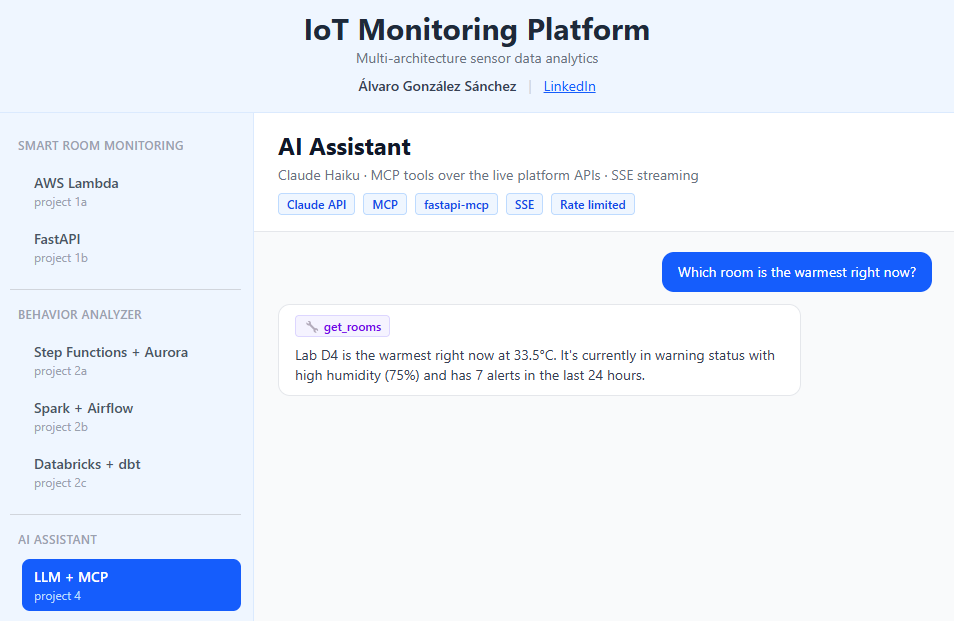
Conversational AI layer over the live platform: Claude answers questions about the real sensor data by calling the platform's own REST APIs, exposed as 7 read-only MCP tools. Bounded agent loop on the streaming Claude API, answers streamed token-by-token via SSE into a chat tab. Security by design: least-privilege container, read-only tool allowlist, per-IP rate limiting.